Fabric pipeline notebook activity
12. Now that you have your data in your lakehouse the next step is to convert these files into delta tables so that you can begin to query this data for analysis. One way to convert your lakehouse files to delta tables is through a notebook. Below is a PySpark notebook that converts the fact and dimension table files into delta tables.
Cell 1 configures the spark session.
spark.conf.set("spark.sql.parquet.vorder.enabled", "true")
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", "true")
spark.conf.set("spark.microsoft.delta.optimizeWrite.binSize", "1073741824")
Cell 2 defines our fact sale table and partitions the data based on the year and quarter columns that have been added.
from pyspark.sql.functions import col, year, month, quarter
table_name = 'fact_sale'
df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full')
df = df.withColumn('Year', year(col("InvoiceDateKey")))
df = df.withColumn('Quarter', quarter(col("InvoiceDateKey")))
df = df.withColumn('Month', month(col("InvoiceDateKey")))
df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)
Cell 3 loads the dimension type tables through a custom function.
from pyspark.sql.types import *
def loadFullDataFromSource(table_name):
df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name)
df.write.mode("overwrite").format("delta").save("Tables/" + table_name)
full_tables = [
'dimension_city',
'dimension_date',
'dimension_employee',
'dimension_stock_item'
]
for table in full_tables:
loadFullDataFromSource(table)
13. After creating the notebook, navigate back to the pipeline window and add a “Notebook” activity to your existing pipeline. Drag the “On success” green arrow from the “Copy data” activity to your “Notebook” activity.

14. Next, configure your “Notebook” activity. On the “Settings” tab add the notebook you created earlier in the steps above. Your “General” tab should look like this:
- Name: Your notebook name
- Description: Add a description of what your notebook is doing
- Timeout: 0.01:00:00
- Retry: 3
- Retry interval (sec): 30
Your “Settings” tab should look like this:
- Notebook: Your notebook resource
- Base parameters: None to add in this example, however these can be filled in if applicable.
Read here on more detail for passing notebook parameters into data factory pipelines.
15. Now that your “Notebook” activity is configured, save and run your pipeline.
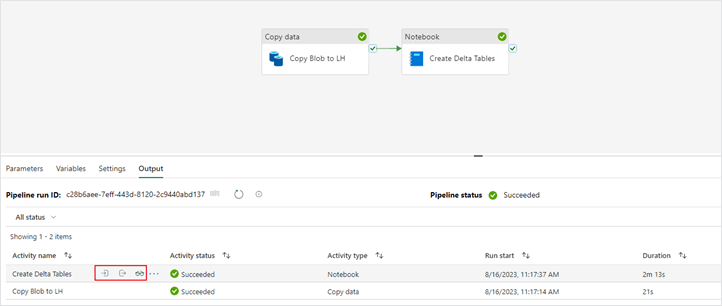
16. With a “Notebook” activity you are able to view a snapshot of the notebook that was executed in the context of the pipeline run.















