Capture pipeline audit data
An important part of the data factory pipeline process is monitoring and auditing your pipeline processes. Luckily, data factory pipelines have some built in variables that allow for an easy capture of this audit data.
- Before capturing the audit data from our pipeline runs, we need to first establish a lakehouse table to store that data. Below are code snippets from a notebook that can be executed to create your audit_pipeline_run delta table:
Cell 1 - Spark configuration
spark.conf.set("spark.sql.parquet.vorder.enabled", "true")
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", "true")
spark.conf.set("spark.microsoft.delta.optimizeWrite.binSize", "1073741824")
Cell 2 – Create delta table
from pyspark.sql.functions import *
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType, ArrayType
schema = StructType([
StructField("PipelineRunId", StringType()),
StructField("PipelineId", StringType()),
StructField("StartTimeUTC", StringType()),
StructField("EndTimeUTC", StringType()),
StructField("WorkspaceId", StringType()),
StructField("PipelineTriggerId", StringType()),
StructField("ParentPipelineRunId", StringType()),
StructField("PipelineCompletedSuccessfully", IntegerType()),
StructField("Process", StringType())
])
data = []
table_name = "audit_pipeline_run"
metadata_df = spark.createDataFrame(data=data, schema=schema)
metadata_df.write.mode("overwrite").option("overwriteSchema", "true").format("delta").save("Tables/" + table_name)
2. Next you will need to create a notebook that inserts and updates your audit record for each pipeline run. This notebook will be called in your data factory pipeline in a later step. Below are code snippets that you will need to save as a notebook in your Fabric workspace:
Cell 1 – Spark configuration
spark.conf.set("spark.sql.parquet.vorder.enabled", "true")
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", "true")
spark.conf.set("spark.microsoft.delta.optimizeWrite.binSize", "1073741824")
Cell 2 – Parameter cell
Important: this cell needs to be toggled as a parameter cell in order to pass values between your notebook and a data factory pipeline.
PipelineRunId = "e3680a99-cb15-41dd-8d4e-2eb3c3e3a315"
PipelineId = "111fb227-7de7-482c-8afa-7277c912d46b"
StartTimeUTC = "8/1/2023 10:59:46"
EndTimeUTC = ""
WorkspaceId = "48cfb6f5-d490-432d-9c9b-42ed05108b4b"
PipelineTriggerId = "4561afd5-d561-641c-9d5b-42e56sa1df4b"
ParentPipelineRunId = "95651dfc6-e954-521c-9d65-6542s5df45b"
PipelineCompletedSuccessfully = 0
Process = "Copy blob storage tables to lakehouse files"

Cell 3 – Delta table merge statement to write pipeline audit data to lakehouse table
from pyspark.sql.functions import *
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType, ArrayType
from datetime import datetime
from delta.tables import *
schema = StructType([
StructField("PipelineRunId", StringType()),
StructField("PipelineId", StringType()),
StructField("StartTimeUTC", StringType()),
StructField("EndTimeUTC", StringType()),
StructField("WorkspaceId", StringType()),
StructField("PipelineTriggerId", StringType()),
StructField("ParentPipelineRunId", StringType()),
StructField("PipelineCompletedSuccessfully", IntegerType()),
StructField("Process", StringType())
])
source_data = [(PipelineRunId, PipelineId, StartTimeUTC, EndTimeUTC, WorkspaceId, PipelineTriggerId, ParentPipelineRunId, PipelineCompletedSuccessfully, Process)]
source_df = spark.createDataFrame(source_data, schema)
display(source_df)
target_delta = DeltaTable.forPath(spark, 'Tables/audit_pipeline_run')
(target_delta.alias('target') \
.merge(source_df.alias('source'), "source.PipelineRunId = target.PipelineRunId")
.whenMatchedUpdate(
set = {"target.EndTimeUTC": "source.EndTimeUTC", "target.PipelineCompletedSuccessfully": "source.PipelineCompletedSuccessfully"}
)
.whenNotMatchedInsert(
values = {
"target.PipelineRunId": "source.PipelineRunId",
"target.PipelineId": "source.PipelineId",
"target.StartTimeUTC": "source.StartTimeUTC",
"target.EndTimeUTC": "source.EndTimeUTC",
"target.WorkspaceId": "source.WorkspaceId",
"target.PipelineTriggerId": "source.PipelineTriggerId",
"target.ParentPipelineRunId": "source.ParentPipelineRunId",
"target.PipelineCompletedSuccessfully": "source.PipelineCompletedSuccessfully",
"target.Process": "source.Process"
})
.execute()
)
3. Once your notebook is created, head back to your data pipeline and add a “Notebook” activity. In the “Settings” menu of your notebook activity, first add your notebook in the dropdown menu. Next, configure the same parameters you defined in cell two of your notebook (see above). Define the parameter values in the expression builder.
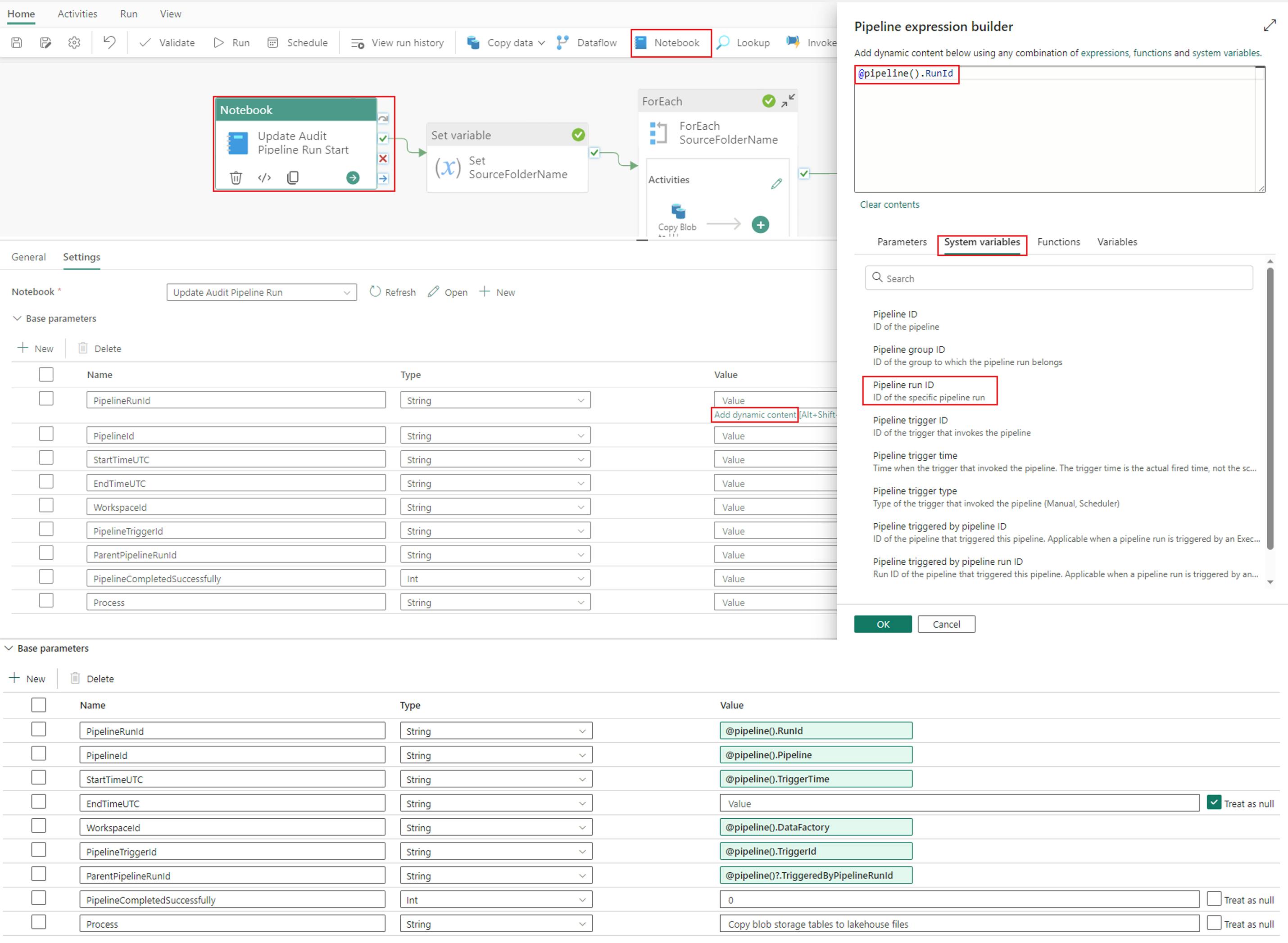
Base parameters:
- PipelineRunId = @pipeline().RunId
- PipelineId = @pipeline().Pipeline
- StartTimeUTC = @pipeline().TriggerTime
- EndTimeUTC = Treat as Null
- WorkspaceId = @pipeline().DataFactory
- PipelineTriggerId = @pipeline().TriggerId
- ParentPipelineRunId = @pipeline()?.TriggeredByPipelineRunId
- PipelineCompletedSuccessfully = 0
- Process = Copy blob storage tables to lakehouse files
4. After configuring this “Notebook” activity, copy and paste it at the end of your pipeline. Update the EndTimeUTC and PipelineCompletedSuccessfully parameters to reflect a successful pipeline run.
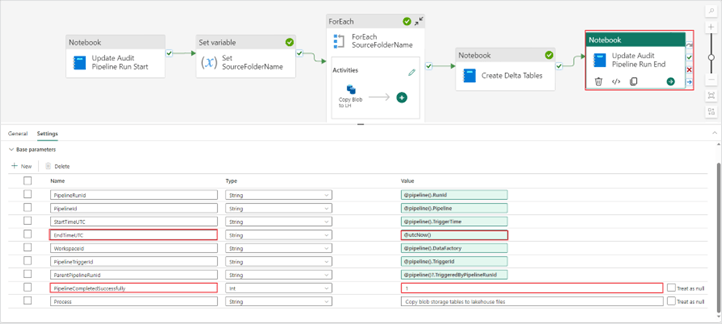
Base parameter changes:
- EndTimeUTC = @utcNow()
- PipelineCompletedSuccessfully = 1
5. Finally save and run your pipeline. Navigate to your audit_pipeline_run table in your lakehouse to confirm the pipeline run data has been captured correctly.
The table record should look like this after the first “Notebook” activity:

The record should then be updated to record a successful run with an EndTimeUTC value if the pipeline run succeeds.





















