
Article
Classifying text with AWS Textract
Feb. 4, 2021
What is AWS Textract?
AWS Textract is an AWS service that allows the user to extract text and data from scanned documents such as insurance forms, loan applications, bank forms or survey questions. Amazon Textract automatically reads and extracts text from the documents and organizes the data into raw text, forms and tables. Enabling the data to either be reviewed by processes downstream or ingested directly into an application or database.

Figure 1: This image describes the business problem that AWS Textract solves
History of the Optical Character Recognition
Let us take a step back and briefly discuss what optical character recognition (OCR) is so that we can understand the impact of AWS Textract. Starting in the late 1800s through the early 1900s, the earliest concepts of OCR were developed to help the blind read. WWII and into the Cold War, OCR tools were used to convert Morse code to text. As time and technology progressed, OCR was used to digitize coupons and postal addresses. OCR’s capabilities grew exponentially with the microprocessor, resulting in additional capabilities such as price tag scanners, passport scanners and the ability to scan historically handwritten textbooks for preservation purposes. Currently, OCR is used in nearly every industry including automatic cameras that read your license plate when you speed through a red light, scanning a check with your phone to deposit it in real time, or even Google Translate when you are in a foreign country and in need of a quick translation of a menu or a sign!
How does OCR work?
Suppose we read a brand-new book. Think about how our eyes differentiate the background from the actual text. We identify the shapes of each letter and each word to form sentences as long as they are legible. We recognize the words and sentences on pages regardless of the print type, such as cursive, block, print or italicized, or font. Our brains are designed to recognize characters. Computers, however, need to be instructed on how to read in the same manner. Think of the letter “A”. Each of us think slightly differently about how the letter “A” is formed, but all versions are acceptable. A computer needs to understand that each one of those forms is equivalent to the letter “A” based on the pixel orientation within a word, sentence and document.
Suppose we have a digital form that a company sends us. Suppose this document is structured in such a way that the first column is the name of a project, the second column is a description, and the third is an amount of revenue. One way we can use an OCR tool is to instruct the computer to “look” in particular blocks. Then, we can have the computer naively look in those blocks and make a determination based on what text is in each block.
AWS Textract features
Amazon Textract is a pre-trained machine-learning model so that you, the user, do not have to reinvent the OCR process for every client or use case. Textract has been trained on millions of documents across a vast spectrum of different document types, such as receipts, sales orders, tax forms, insurance documents or bank loan forms. AWS Textract quickly and accurately extracts data from these scanned forms and documents. Textract automatically detects a document’s layout and key elements on the page, understands the data relationships in any embedded forms or tables, and extracts everything with its context intact. The user can then instantly use the extracted data in an application or store the data in a database.

Figure 2: This process describes the steps that AWS Textract takes when a document is uploaded into AWS Textract
The following are four features of the AWS Textract service that you can use to help assess and understand the Textract process and output.
- Key-value pair extraction: Amazon Textract enables you to detect key-value pairs in document images automatically so that you can retain the inherent context of the document without any manual intervention. This makes it easy to import the extracted data into any format you would like.
- Bounding boxes: All extracted data is returned with bounding box coordinates. The coordinates make up a polygon frame that encompasses each piece of identified data, such as a single word, line, or table. This helps to audit where a word or number’s location is in the source document. It also helps to guide the user in document search systems that return scans of original documents as the search result.
- Table extraction: Amazon Textract preserves the composition of data stored in tables during extraction. This is helpful for documents that are largely composed of structured data, such as medical records that have column names in the top row of the table followed by rows of individual entries.
- Confidence scores: When information is extracted from documents, Amazon Textract returns confidence scores for every word, phrase or table it identifies so that you can make an informed decision about what steps you, the user, want to take next.
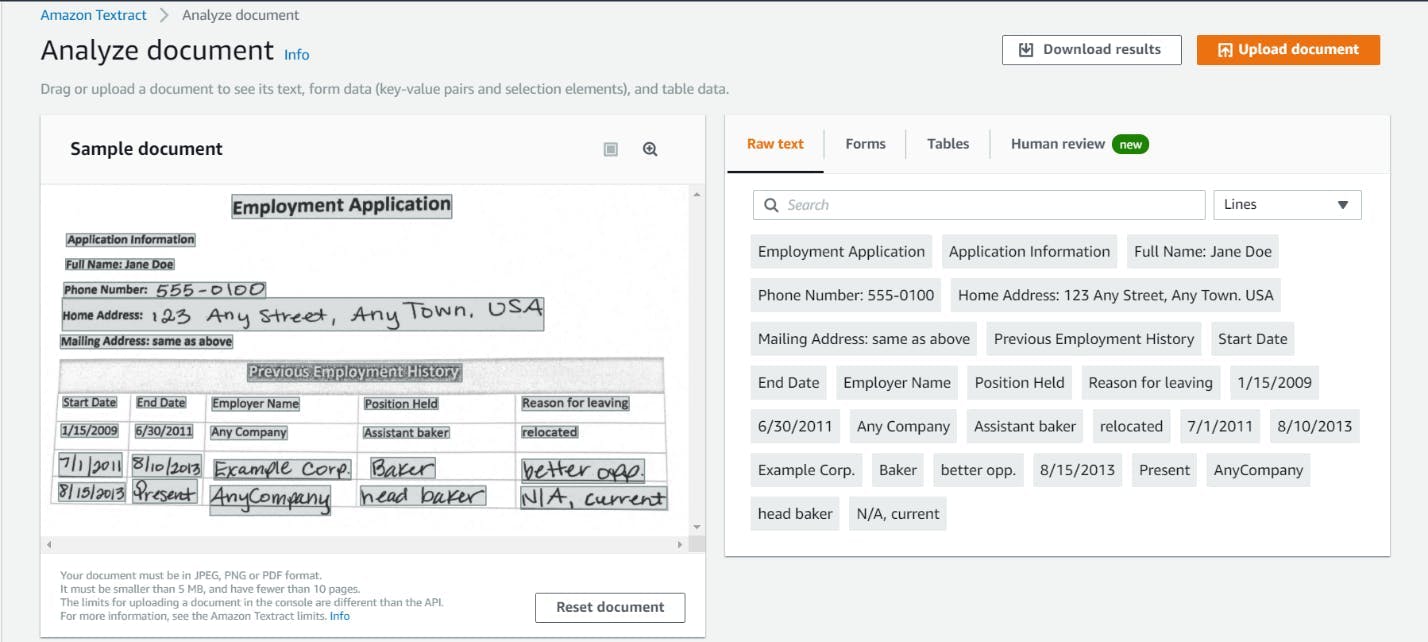
Figure 3: This image displays the AWS Textract console example
Figure 3 shows an example of the AWS Textract console; the “upload document” button allows users to use file explorer to upload an image from their local machine for Textract to analyze. Textract uses natural language processing (NLP) to extract the fields and text within the document provided. The user can also use the Textract API via Boto3 to upload documents. Regardless, AWS Textract provides formatted results (raw text, forms or tables) and allows the user to view the results of the analysis. The results provide the user with confidence scores, bounding boxes and the text with associated fields
AWS Textract has recently released a new feature allowing for handwritten scanned documents to be read. Reading handwritten documents is a distinctly harder problem to solve than digitally printed documents. For digitally printed documents, the NLP algorithms behind Textract look at the different types of fonts and match up the font type to parse out information from the document. However, when analyzing handwritten documents, this is no longer the case. Each individual writes in a unique fashion that is dependent on outside factors (e.g. stress, urgency or device used). Textract will attempt to match up the fonts, however each letter or word now needs to be matched up to a font type instead of establishing it once for a digitally printed document.
AWS Textract requirements
- Use Textract via the console or through the API via Textract Boto3 documentation
- Textract can read JPEG, PNG of up to 10MB and PDF up to 500MB in size type documents
- PDFs cannot have more than 3,000 pages of height 40 inches and width of 2880
- PDF’s cannot be password protected
- PDFs cannot contain JPEG 2000 formatted images as Textract cannot read JPEG 2000 images
- Textract can read any document that has been rotated, but it does not support vertical text alignment within the document undefined
- Textract now supports both handwritten and digitally printed characters
AWS Textract use cases
Let’s explore some examples of the AWS Textract in action to further identify areas the software can aid your business.

Figure 4: This image displays a sample bank statement being uploaded into AWS Textract and the output that the user receives
Figure 4 is a sample bank statement image that was inserted into AWS Textract. On the left side of figure 4 is the originally uploaded image regarding transactions with the First Bank of Wiki. On the right side of figure 4 is the extracted and formatted values from Textract. Each cell from the bank statement has been mapped into table format. AWS Textract converts unstructured bank statement into semi-structured data for download as a CSV or follow-up analysis in AWS SageMaker.

Figure 5: This image displays a document with a form embedded within it and how Textract parses out the form for the user in an intuitive manner
Figure 5 displays an example of a digital form that AWS Textract analyzed. AWS Textract has partitioned out the information from the form and displayed the data into different user-friendly formats. The user is able to extract this information as a CSV or move the extracted data into AWS S3 or AWS SageMaker for additional insights that can help guide your business.
Turning text into strategy
Baker Tilly professionals can help guide you through the intricacies of AWS Textract. Baker Tilly is prepared to assist your business to determine if you can streamline your data with Textract while keeping your future business goal at the forefront of every decision.
Sources:
Article Tags
