
Data movement, processing and orchestration are key to data lake operations
Traditional enterprise data warehouses (EDW) and data marts require days or weeks to plan, design model and develop before data is made visible to end-users. A well-designed data lake balances the structure provided by a data warehouse with the flexibility of a file system. The overall architecture and flow of a data lake can be categorized into three primary pillars: operations, discovery and organization. This article, part of our series on Azure Data Lakes, focuses on the operations aspects of a data lake.
The operations of a data lake involve data movement, processing and orchestration, which we explore in more detail below.
Data movement
Data movement includes the tools, practices and patterns of data ingestion into the data lake. Processing within the data lake and extraction out of the data lake can also be considered data movement, but much attention should be directed at the ingestion level due to the various sources and tool types required. A data lake is often designed to support both batch ingestion as well as streaming ingestion from IoT Hubs, Event Hubs and streaming components.
Three key considerations regarding the ingestion of data into a data lake include:
- Metadata: Metadata can be captured either during the ingestion process or in some sort of batch post process within the data lake. A metadata strategy should already be in place before data ingestion planning begins. The strategy should include knowing what data is going to be captured at ingestion, which can be captured in Azure Data Catalog, HCatalog, or a custom metadata catalog that will support data integration automation as well as data exploration and discovery. The format of the data is also important; what format will be used later in the data lake for processing? It may be more beneficial to use various Hadoop Distributed File System (HDFS) specific files such as AVRO depending on the scenario.
- Batch and real time: Azure Data Lake and associated tools for HDFS allow you to work across thousands of files at petabyte size. A streaming dataset may place small files throughout the day, or a batch process may place one or many terabyte size files per day. Partitioning data at ingestion should be considered and is useful for gaining maximum query and processing performance. Also consider that not all organizational data flows will include a data lake. For example, SSIS packages integrate relational databases with your data warehouse.
- Cloud and on-premise: Many businesses will want to ingest data from both on-premise and cloud sources. It can sometimes be time-consuming to transfer large amounts of data from on-premise systems to Azure. If this becomes a bottleneck, Microsoft provides a private connection to Azure via Azure Express Route.
Processing
Once ingestion of data has been completed, the next step is to begin any processing of the data while it resides in the data lake. This can involve data cleansing, standardization and structuring. Proper data processing tool selection is critical to the success of a data lake.
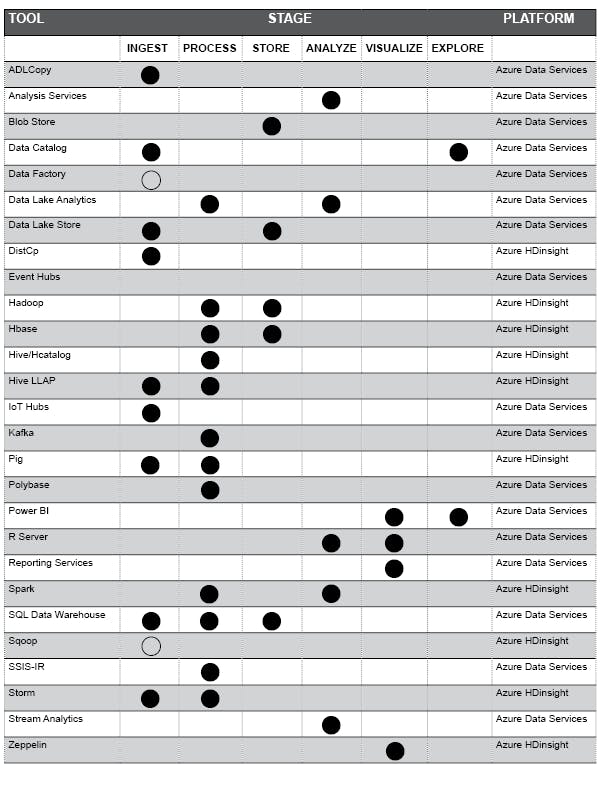
Within Azure, there are two groups of tools available for working with Azure Data Lake: Azure Data Services and Azure HDInsight. Though similar in nature, one is not a direct replacement for the other; sometimes they directly support each other just as a data lake can support an enterprise data warehouse. For most cases, Azure Data Services will be able to solve the lower 80% of data lake requirements, reserving HDInsight for the upper 20% and more complex situations. Azure Data Services allows businesses to acquire and process troves of data as well as gain new insights from existing data assets through machine learning, artificial intelligence and advanced analytics. Open the dropdowns below to learn more about the different processing components.
The following diagram outlines the Azure Data Services and Azure HDInsight tools available for working alongside Azure Data Lake. Though many modern tools have multiple functionalities, the primary use is marked.
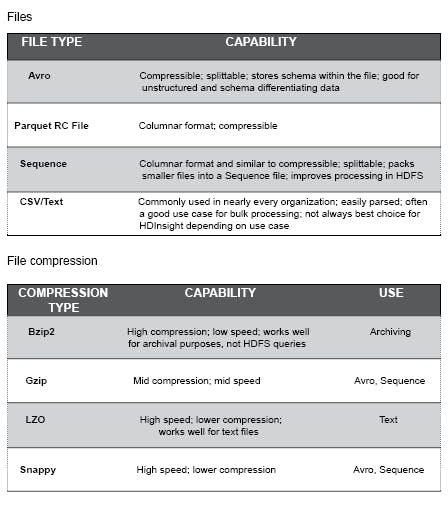
Part of designing a processing pattern across a data lake is choosing the correct file type to use. Listed in the two diagrams below are modern file and compression types. Choosing which type is often a trade-off between speed and compression performance, as well as supported metadata features.
When processing data within Azure Data Lake Store (ADLS), it is common practice to leverage fewer larger files rather than a higher quantity of smaller files. Ideally, you want a partition pattern that will result in the least amount of small files as possible. A general rule of thumb is to keep files around 1GB each, and files per table no more than around 10,000. This will vary based on the solution being developed as well as the processing type of either batch or real-time. Some options for working with small files would be combining them at ingestion and expiring the old (Azure Data Lake has simple functionality for automatically expiring files) or inserting them into a U-SQL or Hive table, and then partitioning and distributing those tables.
U-SQL and Hive processes data in extents and vertices. Vertices are packages of work that are split across the various compute resources working within ADLS. Partitioning distributes how much work a Vertex must do. An extent is essentially a piece of a file being processed, and the vertex is the unit of work.
Table partitioning within Azure Data Lake is a very common practice that brings significant benefits. For example, if we had a directory that is distributed by month, day and the specific files for that day, without partitioning, the queries would have to essentially do a full table scan if we wanted to process the previous month’s data. If we distributed this data by month, we would only have to read 1 out of 12 partitions. Conversely, let’s say we were tracking orders of customers, we would not necessarily want to partition by a customer ID as that could result in many small files which would most likely be the contributor to increased overhead and high utilization of compute and memory resources.
Table distribution is for finer-level partitioning, better known as vertical partitioning. For our last example in discussing table partitioning, we reviewed when we wouldn’t use table partitioning for customer orders. We could however utilize table distribution for something more granular such as customers. Table distribution allows us to define buckets to direct where specific data will live. In a WHERE predicate, the query will know exactly which bucket to go to instead of having to scan each available bucket. Distribution should be configured such that each bucket is similar in size. Remember we still want to avoid many small files here as well.
How will updates be handled? In Azure Data Lake, we cannot update an existing file after it has been created like we would in a traditional relational database system such as SQL Server. Instead, we need to load appended files, and construct our program to view/retrieve the master set plus the appended file or just the appended file. This is what occurs when doing an INSERT. Utilizing a Hive or U-SQL table, we can lay schema across our data files as well as table partitions to drive query performance and functionality. Sometimes it is a better approach to drop and recreate tables instead of trying to manage many small append files.
Orchestration
Orchestration, better understood as simply cloud automation or job automation, is the process of scheduling and managing the execution of processes across multiple systems and the data that flows through those processes.
An example of a big data pipeline across Azure would be ingestion from an event hub where we are capturing factory sensor data, processing that data through Azure Machine Learning and surfacing the results in a Power BI dashboard in real-time. This entire process is orchestrated through Azure Data Factory (ADF). We will refer to workflow automation as orchestration. In the HDInsight environment, some tools are better suited to solving certain problems than others. Therefore, an orchestration solution is what enables us to work across an ever-increasing variety of technology and tools.
It is a common misconception that ADF has replaced mature ETL tools such as SQL Server Integration Services (SSIS). ADF can be understood as a higher-level orchestration layer that can call and pass data to other tools such as SSIS, U-SQL, Azure Machine Learning and more.
How we can help
As one of the three primary pillars in the overall architecture and flow of a data lake, understanding the operations of your data lake is crucial to its success. The movement, processing and orchestration of data in the data lake determines your ability to quickly and efficiently access and apply your data. At Baker Tilly Digital, we help to demystify the process and bring clarity to your data lake configuration, helping you deploy the right technology solutions to provide your business with more actionable insight from its data. To learn more about Baker Tilly Digital can help you better understand the operations of your data lake to gain more meaningful insights from your data, contact one of our professionals today.
